使用Eclipse编译运行MapReduce程序
摘要
大数据技术基础第三次实验
仅供参考
第一部分:实验预习报告
(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验方案与技术路线等)
一、实验目的与意义
- 理解MapReduce编程模型及其在大规模数据集并行计算中的应用。
- 掌握Hadoop框架的基本组成和工作原理。
- 学习在Eclipse集成开发环境中开发MapReduce程序的方法。
- 通过实践加深对大数据技术基础的理解,提高解决实际问题的能力。
二、实验基本原理
- MapReduce 编程模型
MapReduce是一种编程模型,用于大规模数据集的并行计算,由Google提出,后由Apache Hadoop实现。该模型包含两个主要的处理阶段:Map和Reduce。
Map阶段:Map任务负责处理输入数据,将数据转换为中间键值对。Map函数接收输入数据,将其分解为一系列键值对,并输出。
Reduce阶段:Reduce任务处理Map任务的输出,通常对相同键的值进行聚合操作。Reduce函数接收来自Map任务的中间键值对,并将具有相同键的值合并成最终结果。 - Hadoop 框架
Hadoop是一个开源框架,实现了MapReduce模型,允许用户在普通的硬件集群上运行MapReduce程序。Hadoop由两个主要部分组成:
HDFS(Hadoop Distributed File System):一个高度可靠的存储系统,用于存储大规模数据集。
Hadoop MapReduce:一个分布式处理系统,用于处理HDFS上的数据。 - Eclipse 集成开发环境
Eclipse是一个开源的集成开发环境(IDE),支持多种编程语言,包括Java。为了在Eclipse中开发MapReduce程序,需要安装和配置以下插件:
Eclipse IDE:基本的开发环境。
M2Eclipse 插件:用于管理Maven依赖。
Hadoop 插件:用于在Eclipse中运行和调试Hadoop程序。 - 开发 MapReduce 程序
在Eclipse中开发MapReduce程序的步骤如下:
- 创建Maven项目:在Eclipse中创建一个新的Maven项目,用于管理项目依赖。
- 添加Hadoop依赖:在项目的pom.xml文件中添加Hadoop的依赖。
- 编写MapReduce代码:创建Java类,实现MapReduce的Mapper和Reducer接口。
- 打包程序:使用Maven将项目打包成JAR文件。
- 配置Hadoop环境:确保Hadoop环境已正确配置,并且HDFS上存在输入数据。
- Hadoop 2.6.0 环境配置
Hadoop 2.6.0集群的安装与配置涉及到下载Hadoop并解压缩、配置环境变量、配置Hadoop相关配置文件如core-site.xml和hdfs-site.xml等。这些配置文件定义了Hadoop集群的基本属性,如文件系统的默认名称、临时目录的位置、HDFS的副本策略等。 - MapReduce 框架原理
MapReduce框架的核心包括InputFormat、Mapper、Shuffle、Reducer和OutputFormat。InputFormat负责将输入文件切片成多个InputSplit,每个InputSplit对应一个Map任务。Mapper处理输入数据并输出中间键值对。Shuffle阶段包含排序、分区、压缩和合并等操作。Reducer处理Mapper的输出,并将结果输出到文件系统或其他存储系统。
三、主要仪器设备及耗材
- 计算机:安装有Ubuntu/CentOS操作系统的计算机,用于开发和测试MapReduce程序。
- Hadoop环境:Hadoop 2.6.0版本,用于搭建分布式计算环境。
- Eclipse IDE:集成开发环境,用于编写和调试MapReduce程序。
- Hadoop-Eclipse-Plugin:Eclipse插件,用于在Eclipse中直接操作HDFS文件系统和运行MapReduce程序。
四、实验方案与技术路线
1. 实验方案设计
- 环境准备:
o 安装Java开发环境(JDK)。
o 下载并安装Eclipse IDE for Java Developers。
o 安装Hadoop 2.6.0,并按照官方文档进行基本配置,确保HDFS和YARN服务能够正常运行。 - Eclipse配置:
o 在Eclipse中安装M2Eclipse插件,以便管理Maven项目和依赖。
o 安装Hadoop-Eclipse-Plugin,以便在Eclipse中直接操作HDFS和运行MapReduce程序。 - MapReduce程序开发:
o 创建一个新的Maven项目,并配置pom.xml文件,添加Hadoop作为依赖
o 编写MapReduce程序,实现具体的业务逻辑,例如WordCount程序。
o 将Hadoop配置文件(如core-site.xml、hdfs-site.xml和log4j.properties)复制到项目的资源目录下,以确保程序能够正确读取Hadoop配置。 - 程序打包与部署:
o 使用Maven工具将项目打包成JAR文件。
o 将打包好的JAR文件上传到HDFS上,或者在Eclipse中配置运行参数,直接在本地运行。 - 运行与测试:
o 在Eclipse中配置MapReduce程序的运行参数,如输入路径和输出路径。
o 运行MapReduce程序,并监控程序的执行状态。
o 检查HDFS上的输出路径,验证程序的输出结果是否正确。
2. 技术路线
- Hadoop技术栈:
o 利用Hadoop生态系统,包括HDFS和MapReduce,进行大规模数据集的存储和处理。 - Eclipse开发环境:
o 使用Eclipse作为开发环境,通过插件扩展其功能,实现MapReduce程序的开发和调试。 - Maven项目管理:
o 使用Maven进行项目依赖管理,确保项目构建的一致性和可移植性。 - 分布式计算:
o 通过MapReduce模型实现数据的分布式处理,利用集群的计算能力。 - 数据验证与测试:
o 对MapReduce程序的输出结果进行验证,确保数据处理的正确性和程序的稳定性。
第二部分:实验过程记录
(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)
1. 安装Eclipse: 在Ubuntu系统中,通过Ubuntu软件中心搜索并安装Eclipse IDE for Java Developers版。在软件中心的搜索栏中输入“eclipse”,找到软件后点击安装。Eclipse的默认安装目录为/usr/lib/eclipse。
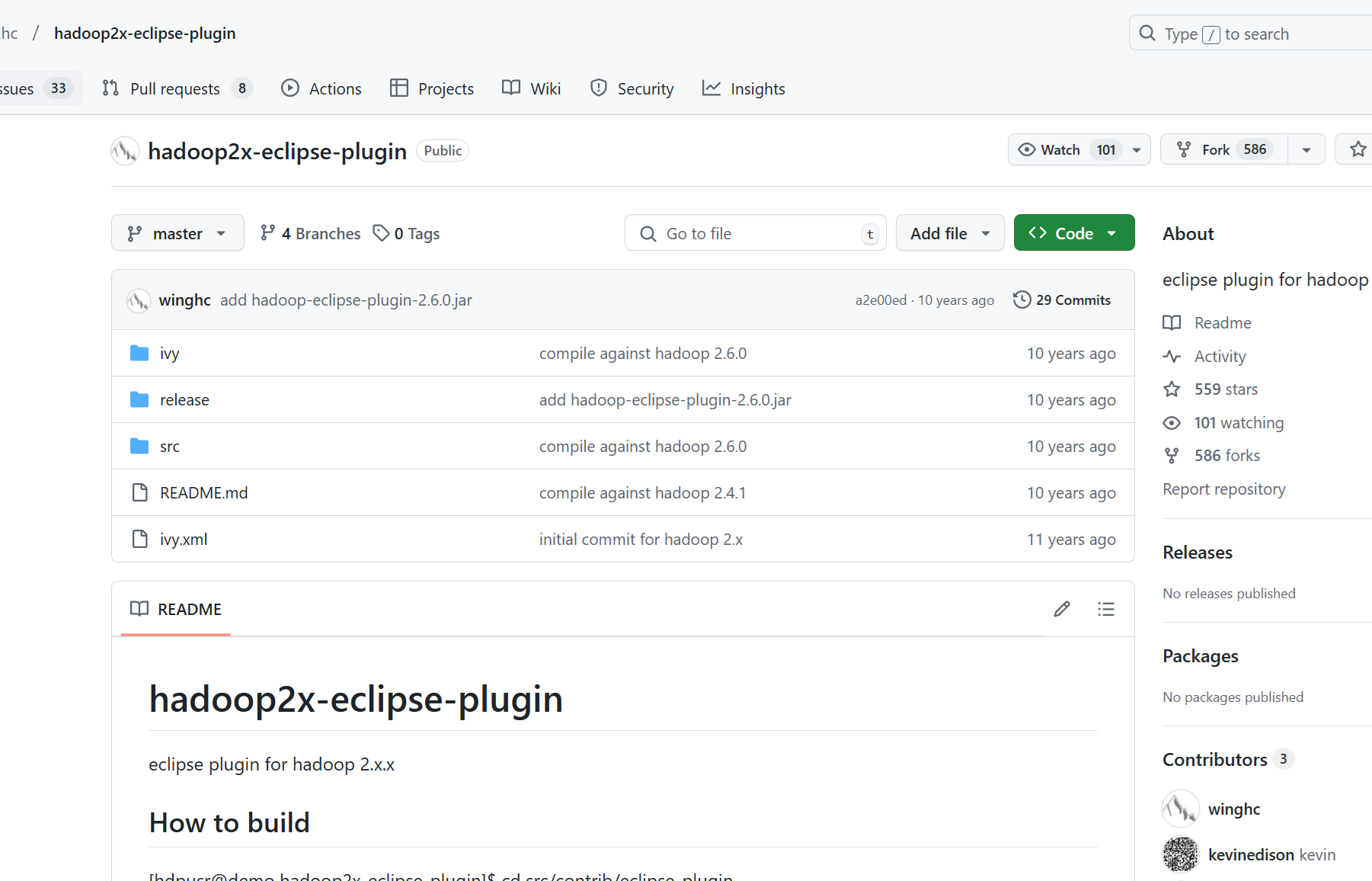
安装Hadoop-Eclipse-Plugin: 为了在Eclipse中编译和运行MapReduce程序,需要安装hadoop-eclipse-plugin。可以从GitHub上的hadoop2x-eclipse-plugin项目下载插件。下载后,将hadoop-eclipse-plugin-2.6.0.jar文件复制到Eclipse安装目录的plugins文件夹中,然后运行eclipse -clean命令重启Eclipse以使插件生效。
配置Hadoop-Eclipse-Plugin:
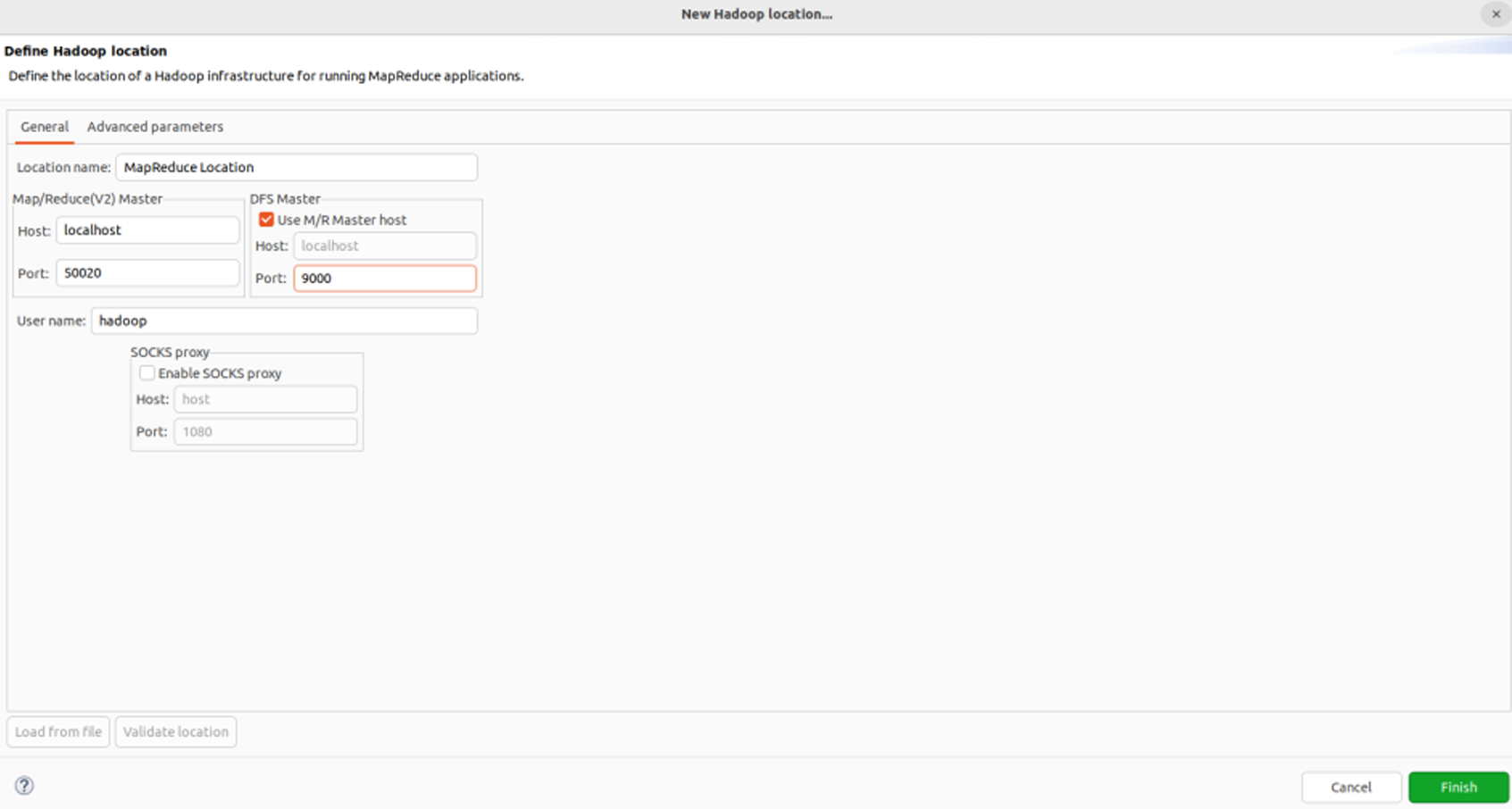
在Eclipse中配置Hadoop-Eclipse-Plugin,首先选择Window菜单下的Preference,然后在弹出的窗体中选择Hadoop Map/Reduce选项,设置Hadoop的安装目录。接着,切换到Map/Reduce开发视图,最后建立与Hadoop集群的连接,在Eclipse软件右下角的Map/Reduce Locations面板中新建Hadoop Location,并配置相关参数。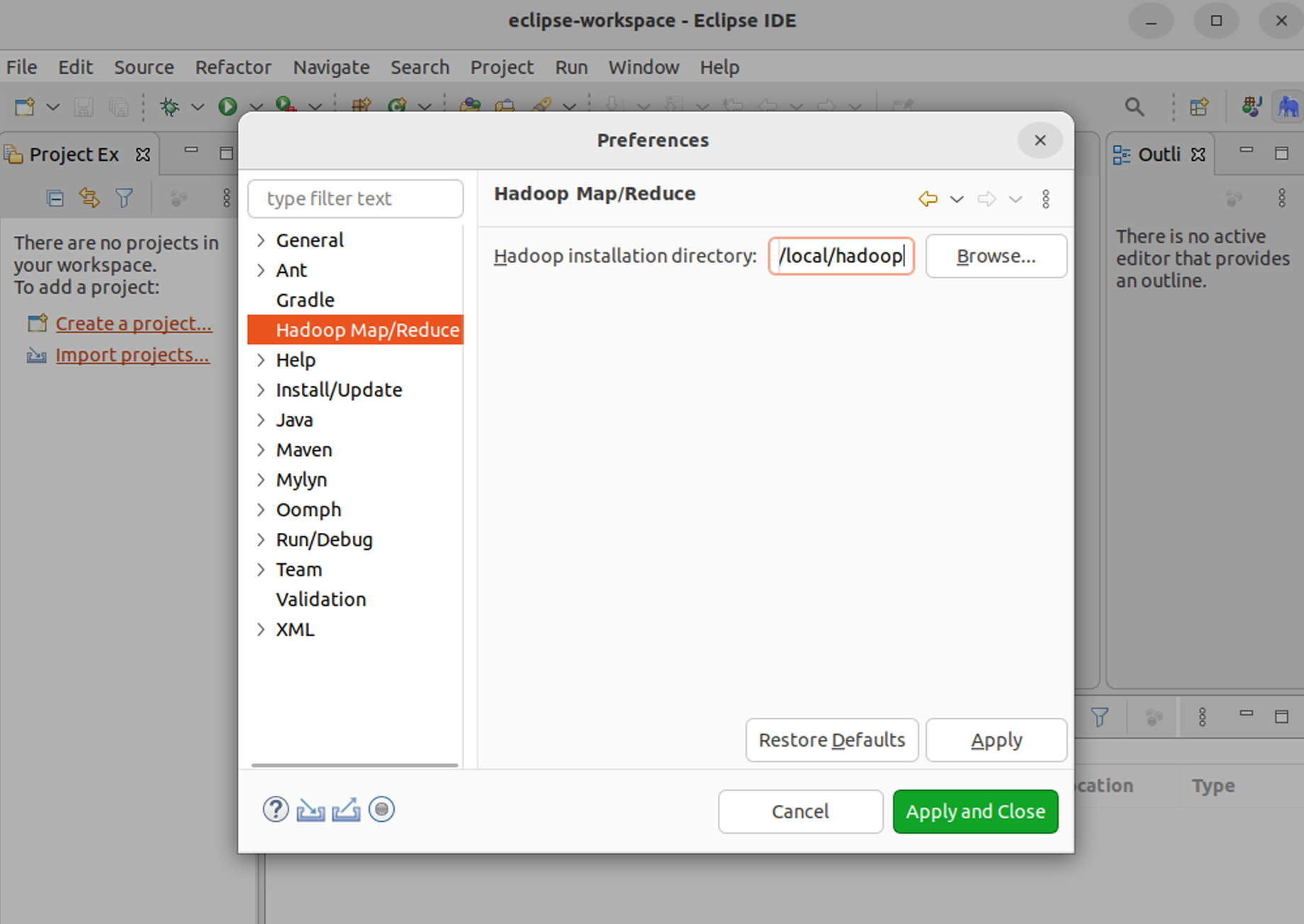
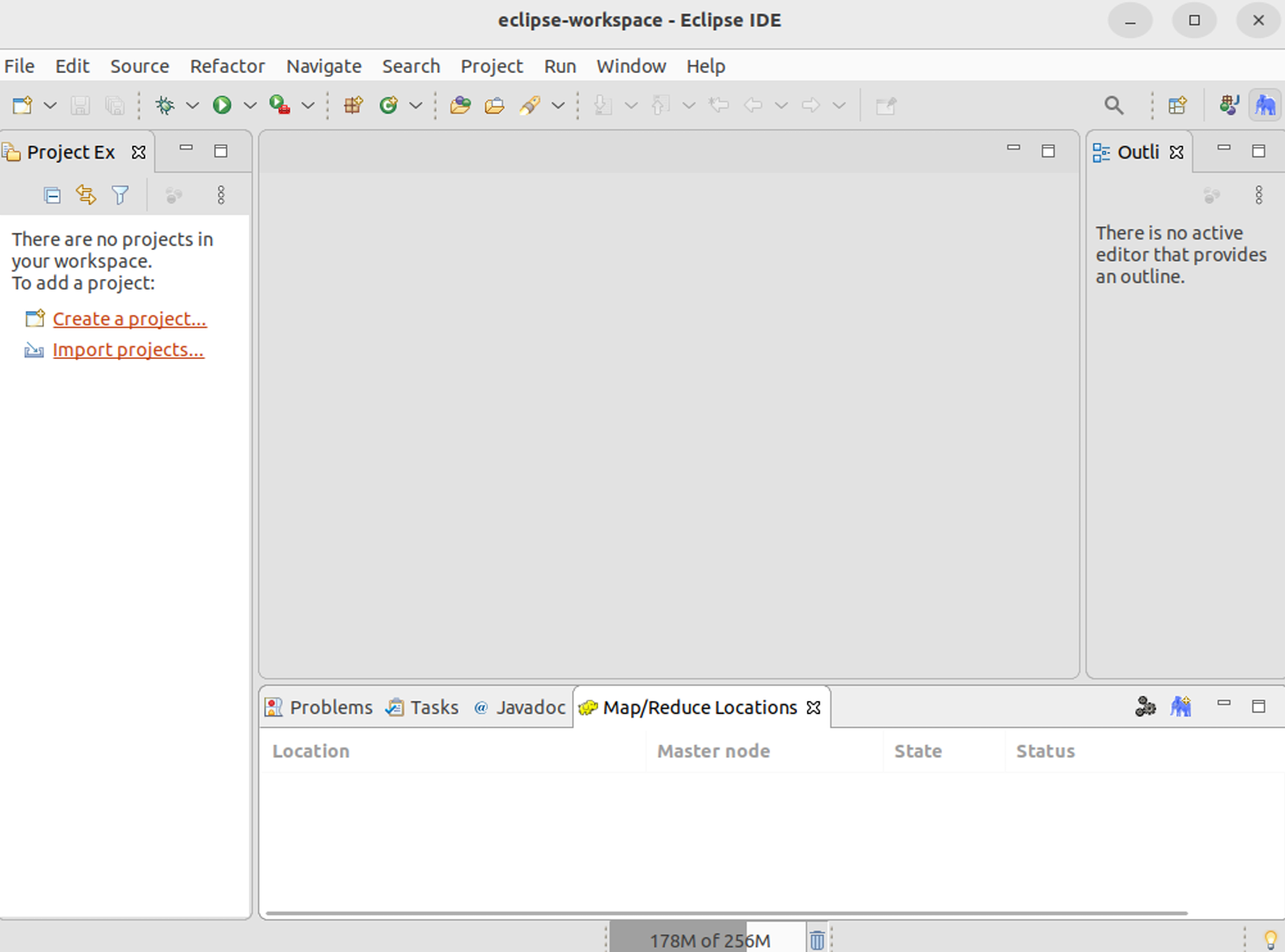
配置好Hadoop-Eclipse-Plugin后,可以在Eclipse的左侧Project Explorer中查看HDFS中的文件列表,双击文件可以查看内容,右键点击可以进行上传、下载、删除等操作,无需使用hdfs dfs命令。
- 创建MapReduce项目:
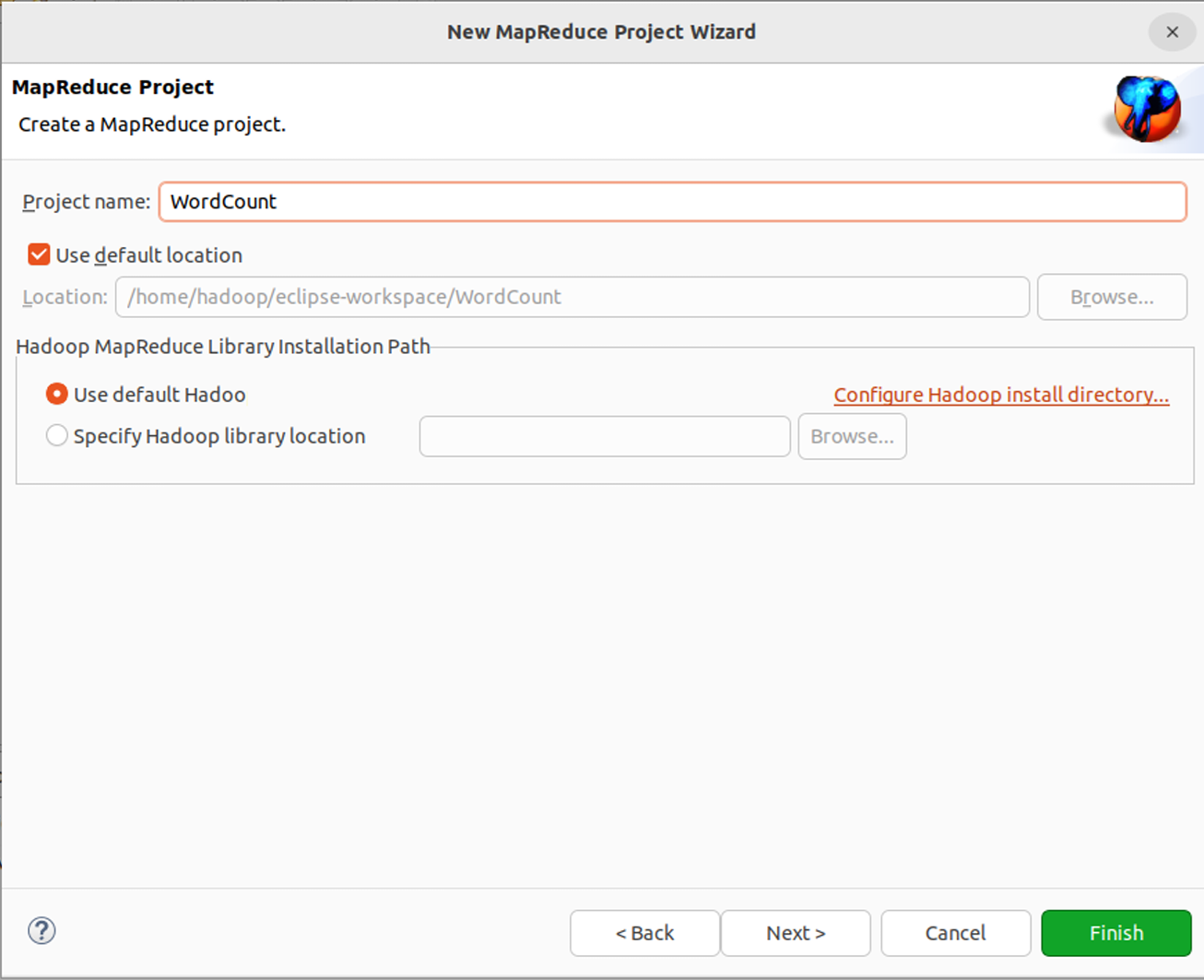
在Eclipse中创建一个新的MapReduce项目,通过File菜单选择New -> Project…,选择Map/Reduce Project,填写项目名为WordCount,点击Finish完成项目创建。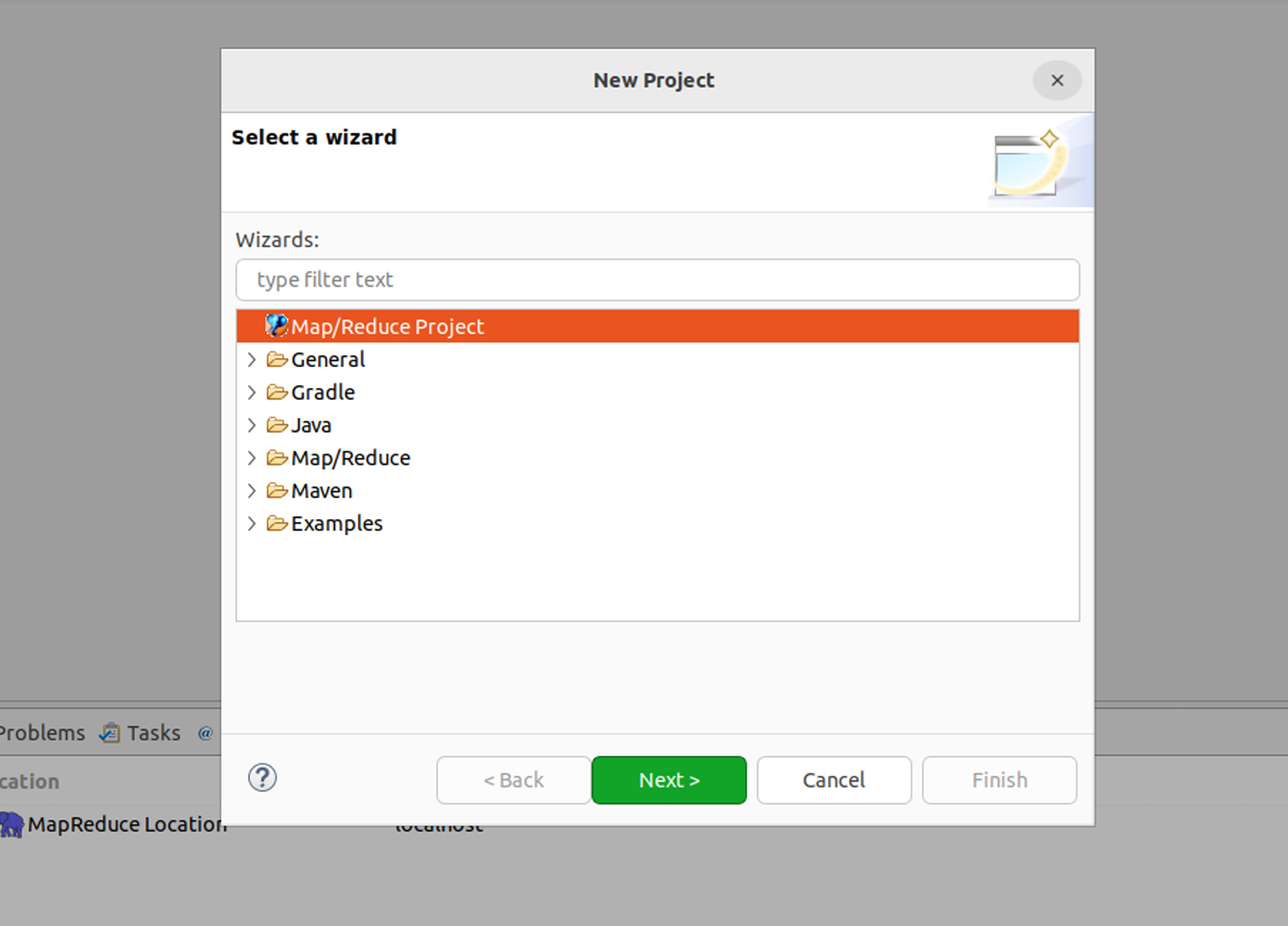
在运行MapReduce程序前,需要将Hadoop的配置文件(如core-site.xml、hdfs-site.xml和log4j.properties)复制到WordCount项目下的src文件夹中,以覆盖默认参数。复制完成后,右键点击WordCount选择refresh刷新项目,然后点击工具栏中的Run图标或右键选择Run As -> Run on Hadoop来运行MapReduce程序。
5. 编写MapReduce代码: 将WordCount程序的代码复制到项目中。
1 | package org.apache.hadoop.examples; |
- 运行MapReduce程序: 通过Eclipse运行WordCount程序,并设置运行参数。
第三部分 结果与讨论
一、实验结果分析
- 成功在Ubuntu系统中安装了Eclipse IDE for Java Developers,并配置了Hadoop-Eclipse-Plugin,使得我们能够在Eclipse中直接操作HDFS文件系统和运行MapReduce程序。
- 创建了名为WordCount的MapReduce项目,并编写了相应的Mapper和Reducer类。程序的主要功能是统计输入文本中每个单词的出现次数。
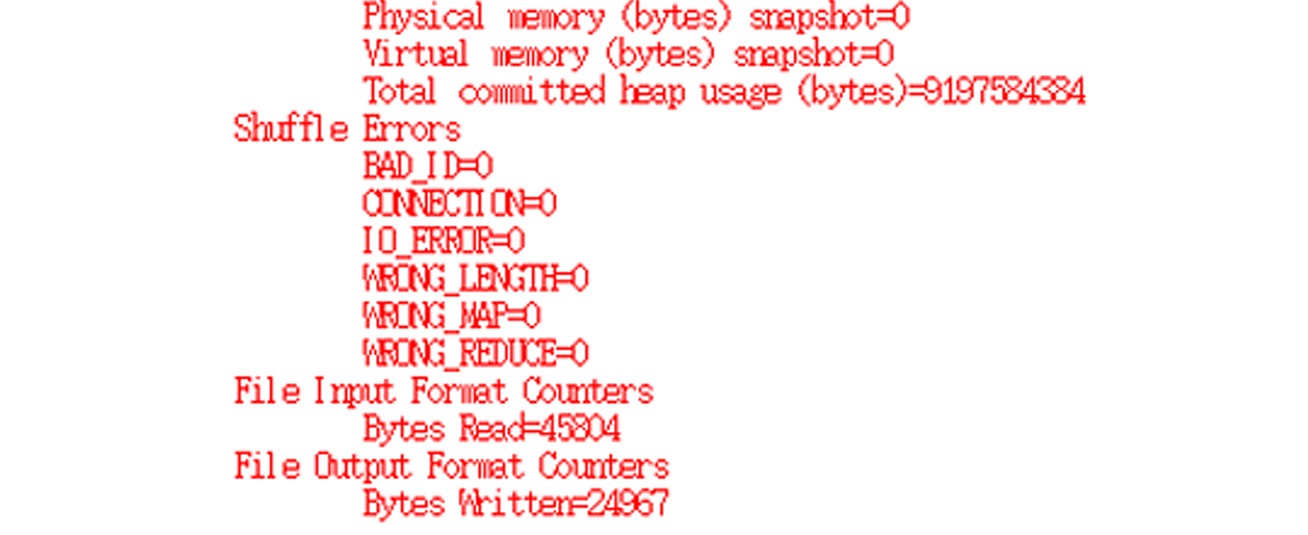
- 通过Eclipse运行WordCount程序,我们设置了输入路径和输出路径。程序运行结束后,检查了HDFS上的输出路径,验证了程序的输出结果是否正确。
- 实验结果显示,WordCount程序正确地统计了输入文本中每个单词的出现次数,并将结果输出到了指定的HDFS目录中。
二、小结、建议及体会
在本次大数据技术基础实验中,我们获得了宝贵的知识和实践经验。首先,我们深入理解了MapReduce编程模型,这一模型在大规模数据集的并行计算中扮演着核心角色。通过实验,我们不仅掌握了Hadoop框架的基本组成,包括其分布式文件系统HDFS和MapReduce编程范式,还学会了如何在Eclipse集成开发环境中高效地开发MapReduce程序,这大大增强了我们解决实际问题的能力。
实验过程中,我们遇到了不少技术挑战,尤其是环境配置错误和程序调试问题。但通过查阅官方文档和在线资源,我们逐步学会了如何独立解决这些问题,这不仅提升了我们的技术能力,也增强了自主学习和问题解决的信心。对此,我们建议未来的实验者在实验前仔细阅读相关文档,深入理解Hadoop的基本概念和架构。此外,尝试安装和配置不同版本的Hadoop,以了解它们之间的差异和兼容性问题,这将是一个很好的学习实践。
通过这次实验,我们深刻体会到大数据技术的深度和广度,以及持续学习的重要性。理论知识虽然重要,但亲自动手实践才能真正理解技术的精髓。实验中遇到的问题提高了我们的问题解决能力,并让我们意识到了在大数据领域中,不断学习和实践是跟上技术发展的关键。总的来说,这次实验不仅加深了我们对Hadoop和MapReduce的理解,也为我们未来在大数据领域的探索和研究打下了坚实的基础。
参考文章:
参考链接
使用Eclipse编译运行MapReduce程序
https://archer314.github.io/2025/12/23/使用Eclipse编译运行MapReduce程序/

