Spark安装和编程实践(Spark2.4.0)
摘要
第四次大数据技术基础实验
仅供参考
第一部分:实验预习报告
(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验方案与技术路线等)
一、实验目的与意义
- 理解Spark编程模型及其在大规模数据集分布式处理中的应用。
- 掌握Spark框架的基本组成和工作原理。
- 学习在集成开发环境中开发Spark程序的方法。
- 通过实践加深对大数据技术基础的理解,提高解决实际问题的能力。
二、实验基本原理
- Spark 概述
Apache Spark 是一个开源的大数据处理通用引擎,它提供了分布式的内存抽象,使得数据处理速度相较于 Hadoop MapReduce 快100倍。Spark 提供了丰富的API,支持多种编程语言,包括Scala、Java、Python和R。 - Spark 核心特性
• 速度快:由于采用内存计算,Spark在处理大数据时速度远超Hadoop MapReduce
• 易用性:Spark 提供了超过80个高级算子,简化复杂数据处理。
• 通用性:适用于批处理、实时流处理、SQL查询和机器学习等多种数据处理场景。
• 可扩展性:能够在从单个机器到数千台机器的集群上运行,处理PB级别的数据 - Spark 编程模型
Spark 的核心是弹性分布式数据集(RDD),它是一个不可变、分布式的数据集合,支持并行操作。RDD支持两种类型的操作:
• 转换(Transformations):如 map、filter、reduceByKey 等,它们会创建一个新的RDD。
• 行动(Actions):如 count、collect、save 等,它们会计算RDD中的所有元素。 - Spark 框架组件
Spark 框架包含以下主要组件:
• Spark Core:提供RDD的创建、操作和动作的基本功能。
• Spark SQL:提供对结构化数据的查询功能,支持SQL查询和Hive查询语言。
• Spark Streaming:提供实时数据流处理的能力,可以将实时数据流转换为RDD进行处理。
• MLlib:提供机器学习算法库,包括分类、回归、聚类等。
• GraphX:提供对图的表示和处理能力,支持图算法和图并行计算。 - Spark 运行模式
Spark 可以在多种模式下运行,包括:
• Local模式:在单台机器上运行,适合开发和测试。
• Standalone模式:在独立的集群上运行,Spark自己管理资源。
• Mesos模式:在Mesos集群上运行,可以与Hadoop共享集群资源。
• YARN模式:在Hadoop YARN集群上运行,可以与Hadoop共享集群资源。 - 开发环境配置
在Eclipse中开发Spark程序,需要安装和配置以下插件:
• Eclipse IDE:基本的开发环境。
• M2Eclipse 插件:用于管理Maven依赖。
• Hadoop 插件:用于在Eclipse中运行和调试Hadoop程序。
三、主要仪器设备及耗材
- 计算机:安装有Ubuntu/CentOS操作系统的计算机,用于开发和测试MapReduce程序。
- Hadoop环境:Hadoop 2.6.0版本,用于搭建分布式计算环境。
- Eclipse IDE:集成开发环境,用于编写和调试MapReduce程序。
- Spark环境:Apache Spark 2.4.0版本,用于实现大数据处理的通用引擎。
四、实验方案与技术路线
环境准备:
1. 安装Java开发环境(JDK):确保Java JDK 1.8已安装,为Spark提供必要的运行环境。
2. 下载并安装Eclipse IDE:安装Eclipse IDE for Java Developers,为开发Spark程序提供集成开发环境。
3. 安装Hadoop:安装Hadoop 3.1.3,并按照官方文档进行基本配置,确保HDFS和YARN服务能够正常运行。
4. 安装Spark:下载并安装Spark 2.4.0,按照文档进行基本配置,使其能够在Local模式下运行。
Eclipse配置:
1. 安装M2Eclipse插件:在Eclipse中安装M2Eclipse插件,以便管理Maven项目和依赖。
2. 安装Hadoop-Eclipse-Plugin:在Eclipse中安装Hadoop插件,以便直接操作HDFS和运行MapReduce程序。
Spark程序开发:
1. 创建Maven/sbt项目:创建一个新的Maven或sbt项目,并配置pom.xml文件添加Spark作为依赖。
2. 编写Spark程序:实现具体的业务逻辑,例如WordCount程序。
3. 配置Hadoop环境:将Hadoop配置文件(如core-site.xml、hdfs-site.xml和log4j.properties)复制到项目的资源目录下,以确保程序能够正确读取Hadoop配置。
程序打包与部署:
1. 使用Maven/sbt打包:使用Maven或sbt工具将项目打包成JAR文件。
2. 上传JAR文件:将打包好的JAR文件上传到HDFS上,或者在Eclipse中配置运行参数,直接在本地运行。
运行与测试:
1. 配置运行参数:在Eclipse中配置MapReduce程序的运行参数,如输入路径和输出路径。
2. 运行程序:运行MapReduce程序,并监控程序的执行状态。
3. 验证输出结果:检查HDFS上的输出路径,验证程序的输出结果是否正确
技术路线
Hadoop技术栈:
• 利用Hadoop生态系统,包括HDFS和MapReduce,进行大规模数据集的存储和处理。
Eclipse开发环境:
• 使用Eclipse作为开发环境,通过插件扩展其功能,实现MapReduce程序的开发和调试。
Maven/sbt项目管理:
• 使用Maven或sbt进行项目依赖管理,确保项目构建的一致性和可移植性
分布式计算:
• 通过MapReduce模型实现数据的分布式处理,利用集群的计算能力。
数据验证与测试:
• 对MapReduce程序的输出结果进行验证,确保数据处理的正确性和程序的稳定性。
第二部分:实验过程记录
(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)
- Spark安装与配置
• 下载Spark安装文件: 访问https://spark.apache.org/downloads.html,选择适合的版本进行下载,或直接从百度云盘下载spark-2.4.0-bin-without-hadoop.tgz文件。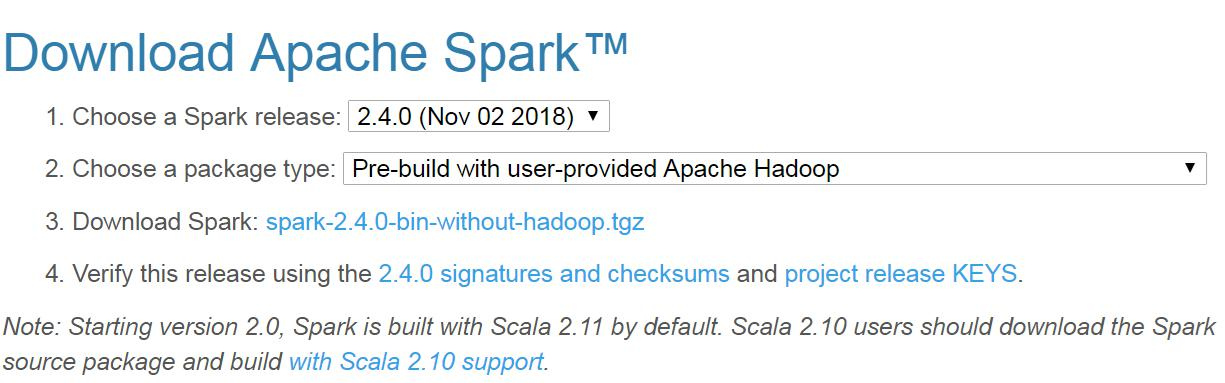
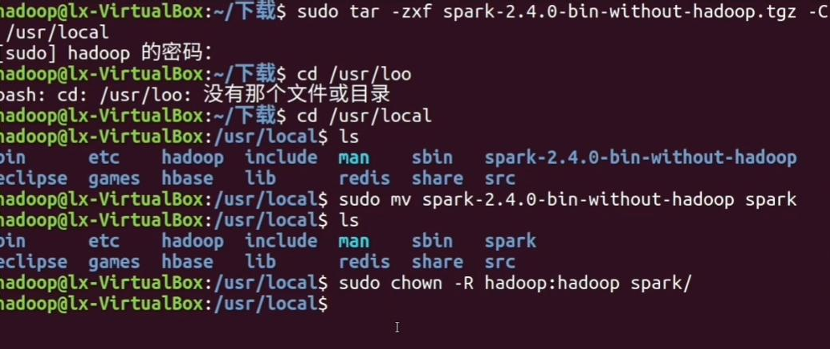
解压安装包: 使用以下Shell命令将下载的文件解压到/usr/local目录下:
1 | sudo tar -zxf ~/下载/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/ |
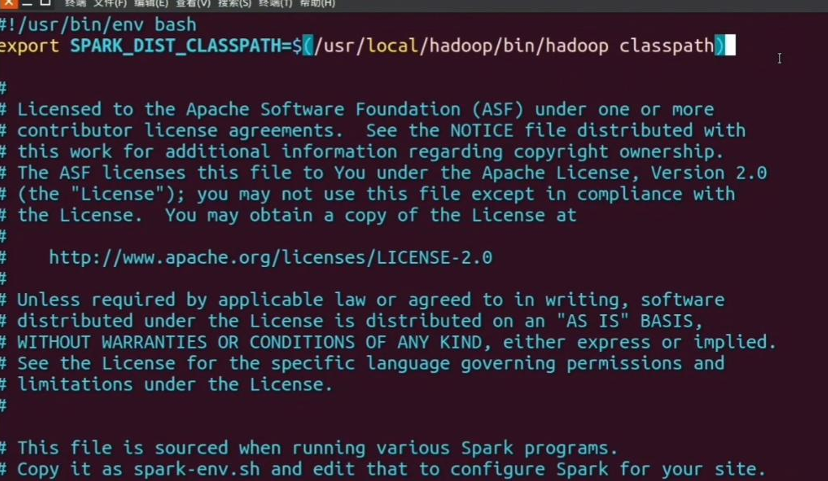
修改Spark配置文件: 复制spark-env.sh.template到spark-env.sh并编辑,在第一行添加Hadoop classpath配置:
1 | cd /usr/local/spark |
编辑spark-env.sh文件:
1 | export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) |
- 验证Spark安装
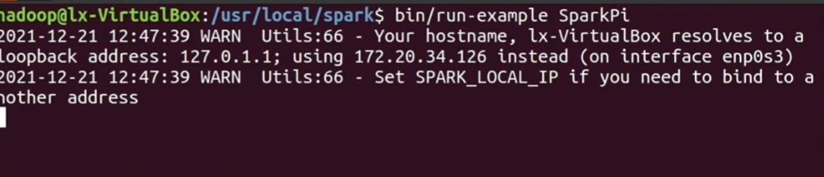
• 运行SparkPi示例程序: 通过执行以下命令运行SparkPi示例程序,验证Spark是否安装成功:
1 | cd /usr/local/spark/bin |
使用grep命令过滤输出结果:
1 | ./run-example SparkPi 2>&1 | grep "Pi is" |

- 使用Spark Shell
• 启动Spark Shell: 使用以下命令启动Spark Shell:
1 | cd /usr/local/spark/bin |
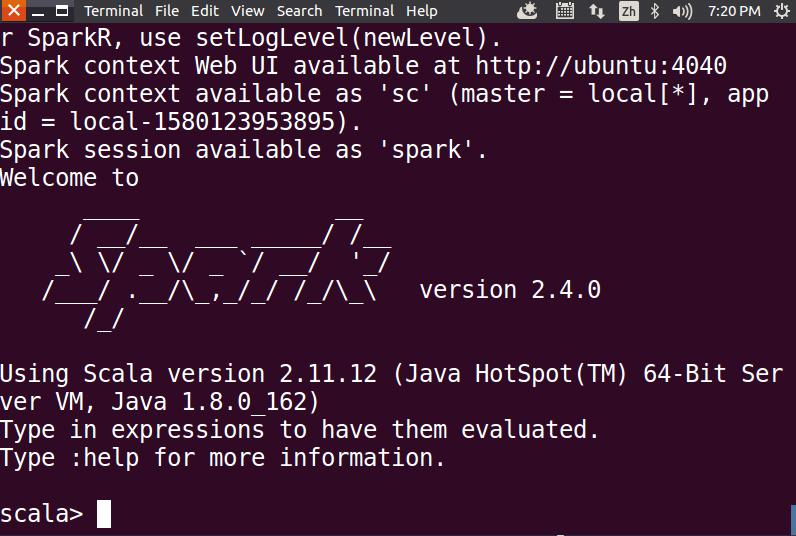
加载text文件: 使用sc.textFile加载本地文件README.md:
1 | val textFile = sc.textFile("file:///usr/local/spark/README.md") |
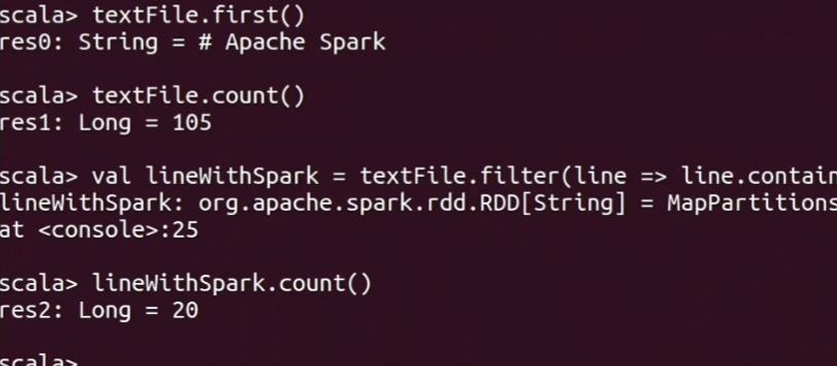
执行RDD操作: 进行基本的RDD操作,如获取第一行内容、计数、过滤等:
1 | textFile.first() |
- 独立应用程序编程
• 使用sbt对Scala独立应用程序进行编译打包:
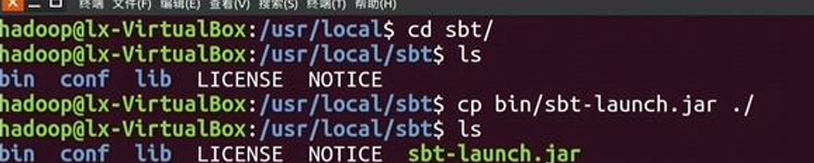
o 安装sbt: 下载并安装sbt:
1 | sudo mkdir /usr/local/sbt |
创建sbt启动脚本并赋予权限:
1 | vim /usr/local/sbt/sbt |
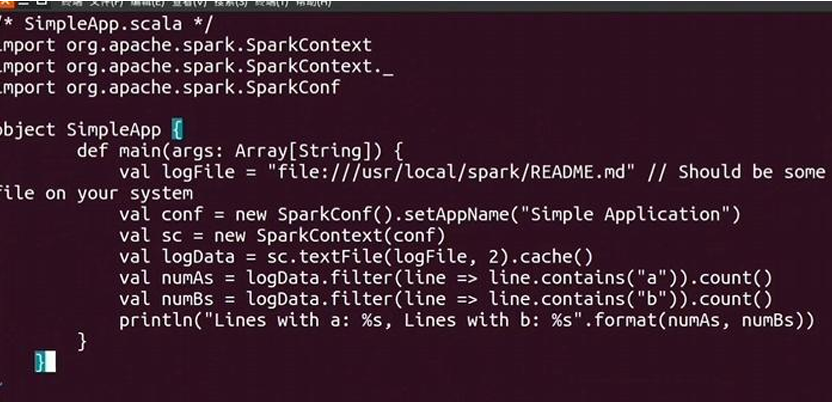
编写Scala应用程序代码: 创建SimpleApp.scala文件并添加代码:
1 | import org.apache.spark.SparkContext |
使用sbt打包Scala程序: 在~/sparkapp目录中新建simple.sbt文件并添加依赖:
1 | name := "Simple Project" |
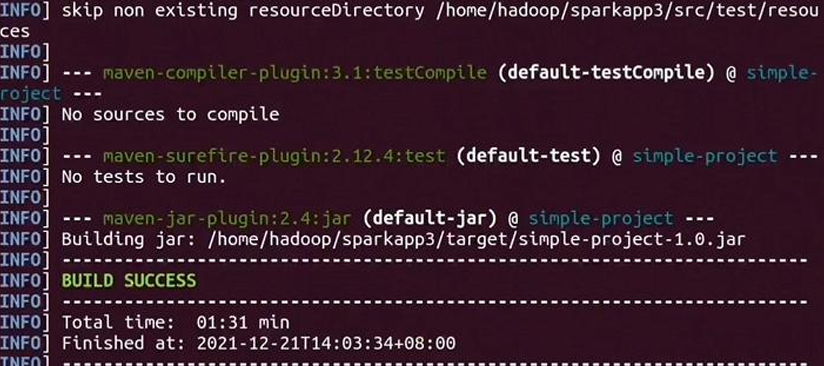
使用sbt打包应用程序:
1 | /usr/local/sbt/sbt package |
通过spark-submit运行程序: 使用以下命令提交JAR包到Spark中运行:
1 | /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar |
过滤输出结果:
1 | /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:" |
最终结果:
1 | Lines with a: 62, Lines with b: 31 |
第三部分 结果与讨论(可加页)
一、实验结果分析
- Spark安装验证:通过运行SparkPi示例程序,成功得到π的近似值,确认Spark安装成功。
- RDD基本操作:Spark Shell中进行的文件读取、行数统计和内容过滤等操作均返回预期结果,展示了RDD的基本处理能力。
- 独立应用程序运行:Scala编写的SimpleApp程序能够正确计算并输出特定字符的行数,验证了Spark API的功能和独立应用程序的运行流程。
二、小结、建议及体会
在本次实验中,我们成功地安装并配置了Apache Spark 2.4.0环境,并在单机上以Local模式进行运行,通过这一过程我们深入了解了Spark的编程模型、框架组件以及在集成开发环境中开发Spark应用程序的方法。实验覆盖了从环境搭建到程序开发、打包、部署和测试的整个流程,这不仅增强了我们对Spark大数据处理能力的认识,也提升了我们的技术实践能力。通过实践,我们体会到了Spark技术在处理大规模数据集时的高效性能,同时也认识到了学习Spark技术的重要性和必要性。
此外,实验过程中我们也遇到了不少挑战,尤其是在环境配置和程序调试方面。这些挑战虽然一开始让我们感到困难,但通过查阅官方文档、社区资源和不断尝试,我们逐步学会了如何独立解决问题。这个过程不仅提高了我们的技术能力,也增强了我们自主学习和问题解决的信心。我们建议未来的实验者在实验前仔细阅读相关文档,深入理解Spark的基本观念和架构,并尝试安装和配置不同版本的Spark,以了解它们之间的差异和兼容性问题。
总的来说,这次实验不仅加深了我们对Spark和大数据处理技术的理解,也为我们未来在大数据领域的探索和研究打下了坚实的基础。我们深刻体会到大数据技术的深度和广度,以及持续学习的重要性。理论知识虽然重要,但亲自动手实践才能真正理解技术的精髓。实验中遇到的问题提高了我们的问题解决能力,并让我们意识到了在大数据领域中,不断学习和实践是跟上技术发展的关键。
参考文章:
参考链接
Spark安装和编程实践(Spark2.4.0)
https://archer314.github.io/2025/12/23/Spark安装和编程实践(Spark2-4-0)/

