Hadoop的安装与伪分布式测试
摘要
大数据技术基础第二次实验报告
仅供参考
第一部分:实验预习报告
(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验方案与技术路线等)
一、实验目的与意义
- 掌握Hadoop安装:使学习者能够理解并独立完成Hadoop在Ubuntu系统上的安装过程。
- 理解Hadoop配置:让学习者了解Hadoop的配置文件和参数,以及如何根据需要修改配置。
- 熟悉Linux操作:通过安装过程加深对Linux系统操作的熟悉度,为后续的大数据技术学习打下基础。
- 实践大数据处理:通过Hadoop的安装与配置,为实际的大数据处理任务做准备
二、实验基本原理
- Hadoop是一个开源的大数据处理框架,它允许跨多个机器使用分布式处理大数据集。Hadoop的核心是HDFS(Hadoop Distributed File System)和MapReduce编程模型。HDFS提供了一个高度可靠的存储系统,而MapReduce则提供了一个高效的数据处理模型。本教程主要基于原生Hadoop 2,包括Hadoop 2.6.0和2.7.1等版本,通过详细步骤和适当说明,帮助用户理解Hadoop的安装和配置过程。
- Hadoop架构
HDFS(Hadoop Distributed File System):Hadoop的分布式文件系统,设计用于在大规模硬件集群上存储大量数据。HDFS将文件分割成多个块(默认为128MB),并将这些块分散存储在集群的不同节点上,从而提供高吞吐量的数据处理和高可靠性的数据存储。
MapReduce:Hadoop的分布式处理框架,它通过Map和Reduce两个步骤来处理大规模数据集。Map步骤负责将输入数据转换为键值对,而Reduce步骤则对这些键值对进行归并和处理,以产生最终结果。 - Hadoop 2.x版本引入了YARN(Yet Another Resource Negotiator),负责集群资源管理和任务调度,提高了系统的可扩展性和灵活性。
- 分布式存储
数据复制:HDFS通过在不同节点上复制数据块来提高数据的可靠性。默认情况下,每个数据块会有三份复制,存放在不同的节点上,以防止硬件故障导致数据丢失。
高吞吐量:HDFS优化了数据的读写操作,使其适合于大规模数据集的批量处理。它通过在多个节点上并行处理数据来实现高吞吐量。 - 分布式计算
MapReduce编程模型:MapReduce允许开发者编写可以在多个节点上并行运行的Map和Reduce函数,从而实现对大规模数据集的并行处理。
大规模数据处理:MapReduce框架能够有效地处理PB级别的数据集,通过将任务分配到集群中的多个节点上,实现大规模数据的快速处理。 - Java环境依赖
Java运行环境:Hadoop是用Java语言编写的,因此需要Java运行环境来执行Hadoop的各个组件。
环境变量配置:为了使系统能够找到Java的执行路径,需要设置JAVA_HOME环境变量,指向Java安装目录。此外,还需要将Java的bin目录添加到系统的PATH变量中,以便在任何位置都能调用Java命令。
三、主要仪器设备及耗材
硬件资源
- 计算机或服务器:至少需要一台计算机作为Hadoop的安装和运行环境,如果是进行集群配置,则需要多台计算机。
- 存储设备:足够的硬盘存储空间用于安装Hadoop及其数据存储。
- 网络设备:网卡和网络连接设备,用于节点间的通信。
软件资源
- 操作系统:Ubuntu 22.04 64位作为Hadoop运行的操作系统环境。
- Java开发包(JDK):Hadoop需要Java环境来运行,因此需要安装JDK。
- SSH服务:用于无密码登录和远程管理Hadoop集群。
- Apache Hadoop:Hadoop的安装包,可以从Apache官网或镜像站点下载。
- 文本编辑器: gedit,用于编辑配置文件。
四、实验方案与技术路线
- 环境搭建:在Ubuntu系统上创建hadoop用户,为Hadoop安装和配置做准备。
- 系统更新:更新apt包管理器,确保软件包的最新状态。
- 依赖安装:安装SSH服务以实现无密码登录,安装Java环境作为Hadoop运行的基础。
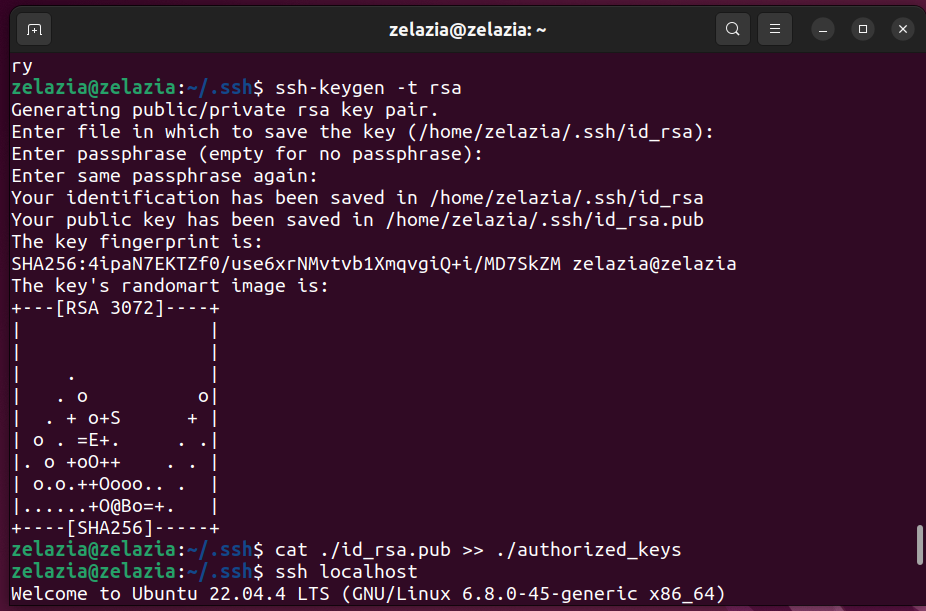
- SSH无密码登录配置:配置SSH密钥,实现本机无密码登录。
- Hadoop安装:下载Hadoop安装包,解压并设置环境变量。
- 单机模式配置:Hadoop默认支持单机模式,无需额外配置即可运行。
- 伪分布式配置:
修改core-site.xml和hdfs-site.xml配置文件。
格式化NameNode。
启动Hadoop的NameNode和DataNode守护进程。 - 运行Hadoop实例:
在HDFS中创建用户目录。
将配置文件复制到HDFS中。
运行MapReduce示例程序。 - YARN配置(可选):
修改mapred-site.xml和yarn-site.xml配置文件。
启动YARN和历史服务器。 - PATH环境变量配置:将Hadoop的可执行文件路径添加到PATH环境变量中,方便命令行操作。
第二部分:实验过程记录
(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)
一、实验准备阶段
- 环境搭建:
确保使用的是Ubuntu 64位系统。
创建名为hadoop的新用户,给予必要的权限。 - 更新系统包:
执行sudo apt-get update命令更新系统包。
- 安装SSH服务:
安装openssh-server以实现无密码登录。
- 安装Java环境:
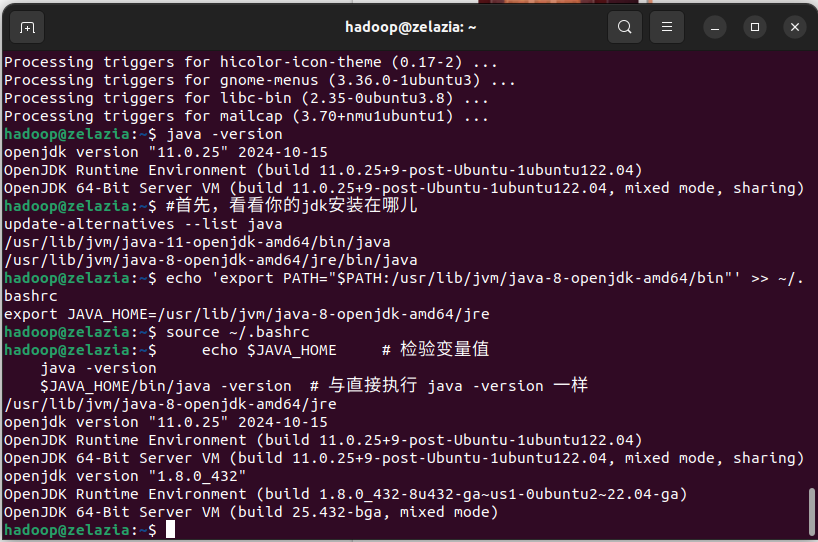
选择一种方式安装JDK,并配置JAVA_HOME环境变量。 - 下载Hadoop:
从官方网站或提供的百度云盘链接下载Hadoop安装包。 - 解压Hadoop:
将下载的Hadoop包解压到/usr/local/目录下,并重命名文件夹为hadoop。
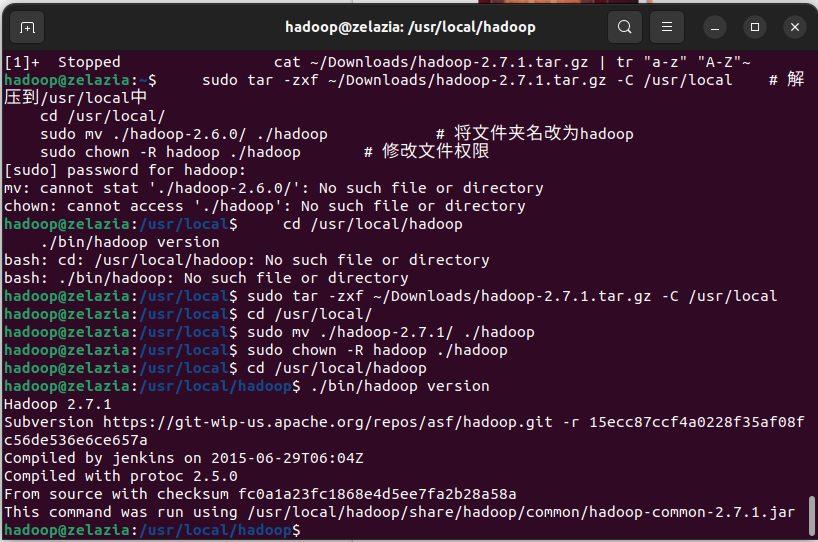
二、Hadoop单机配置
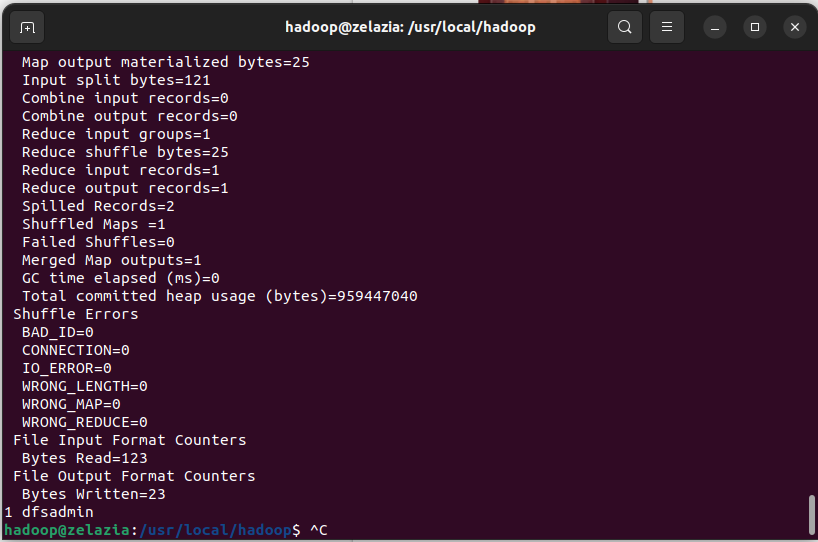
- 非分布式模式运行:
直接运行Hadoop附带的例子程序,体验单机模式下的MapReduce作业。
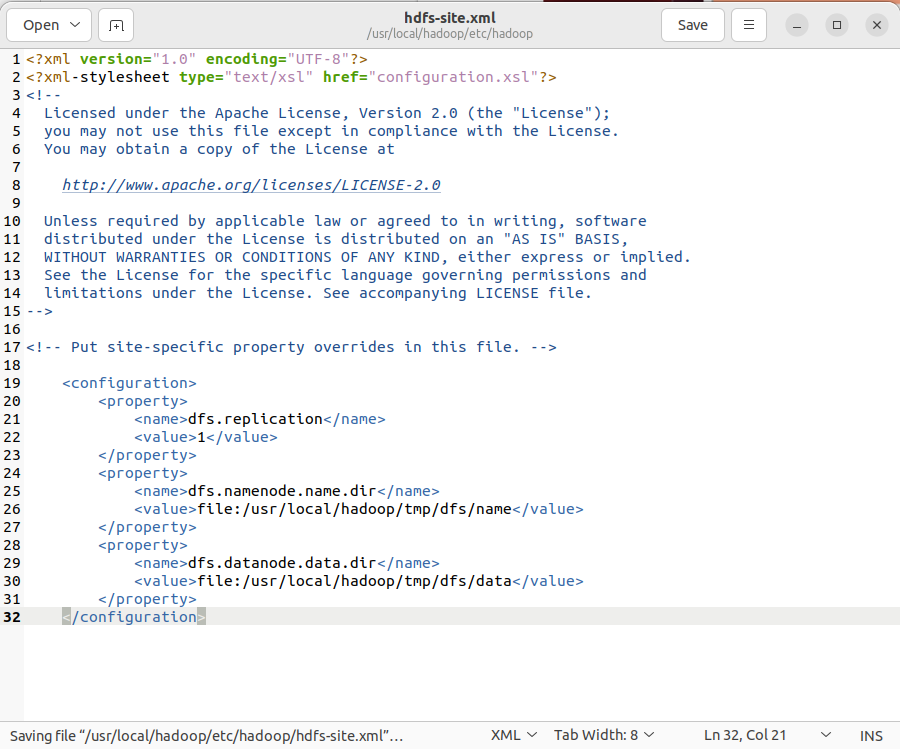
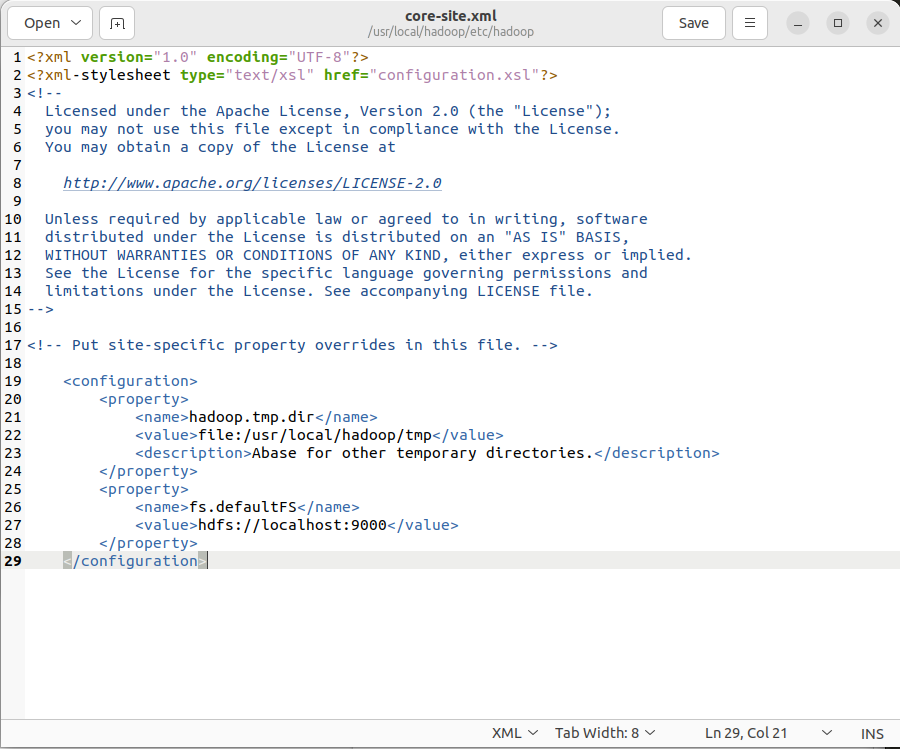
- 配置HDFS:
修改core-site.xml和hdfs-site.xml配置文件,设置HDFS的存储路径和文件系统。
- 格式化NameNode:
执行hdfs namenode -format命令格式化HDFS文件系统。 - 启动Hadoop守护进程:
执行start-dfs.sh脚本启动Hadoop的NameNode和DataNode。
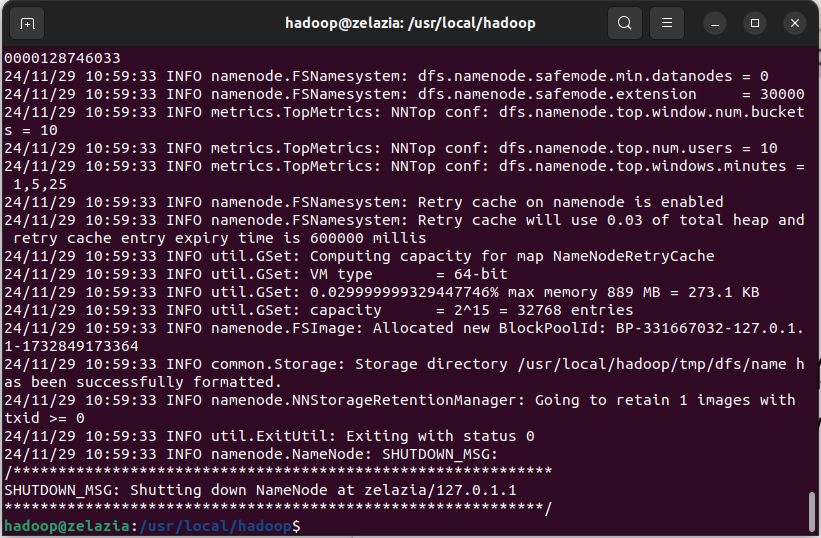
三、Hadoop伪分布式配置
- 修改配置文件:
根据伪分布式的需求,修改core-site.xml和hdfs-site.xml配置文件。
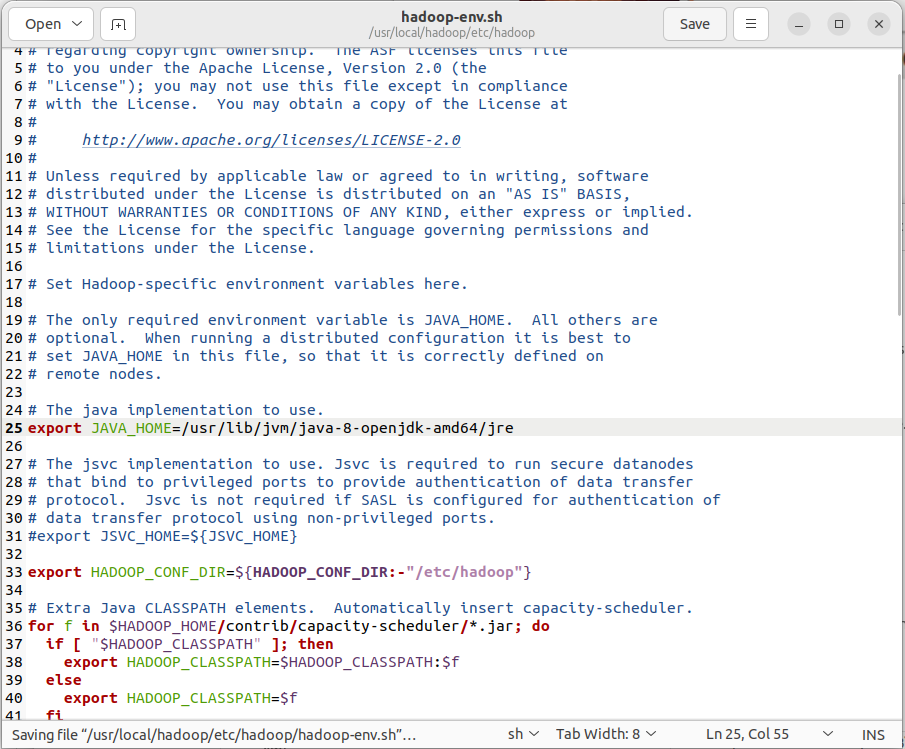
- 启动Hadoop:
再次执行start-dfs.sh脚本启动Hadoop。 - 运行MapReduce作业:
将数据上传到HDFS,并在HDFS上运行MapReduce作业。 - 查看结果:
使用hdfs dfs -cat命令查看MapReduce作业的输出结果。
第三部分 结果与讨论
一、实验结果分析
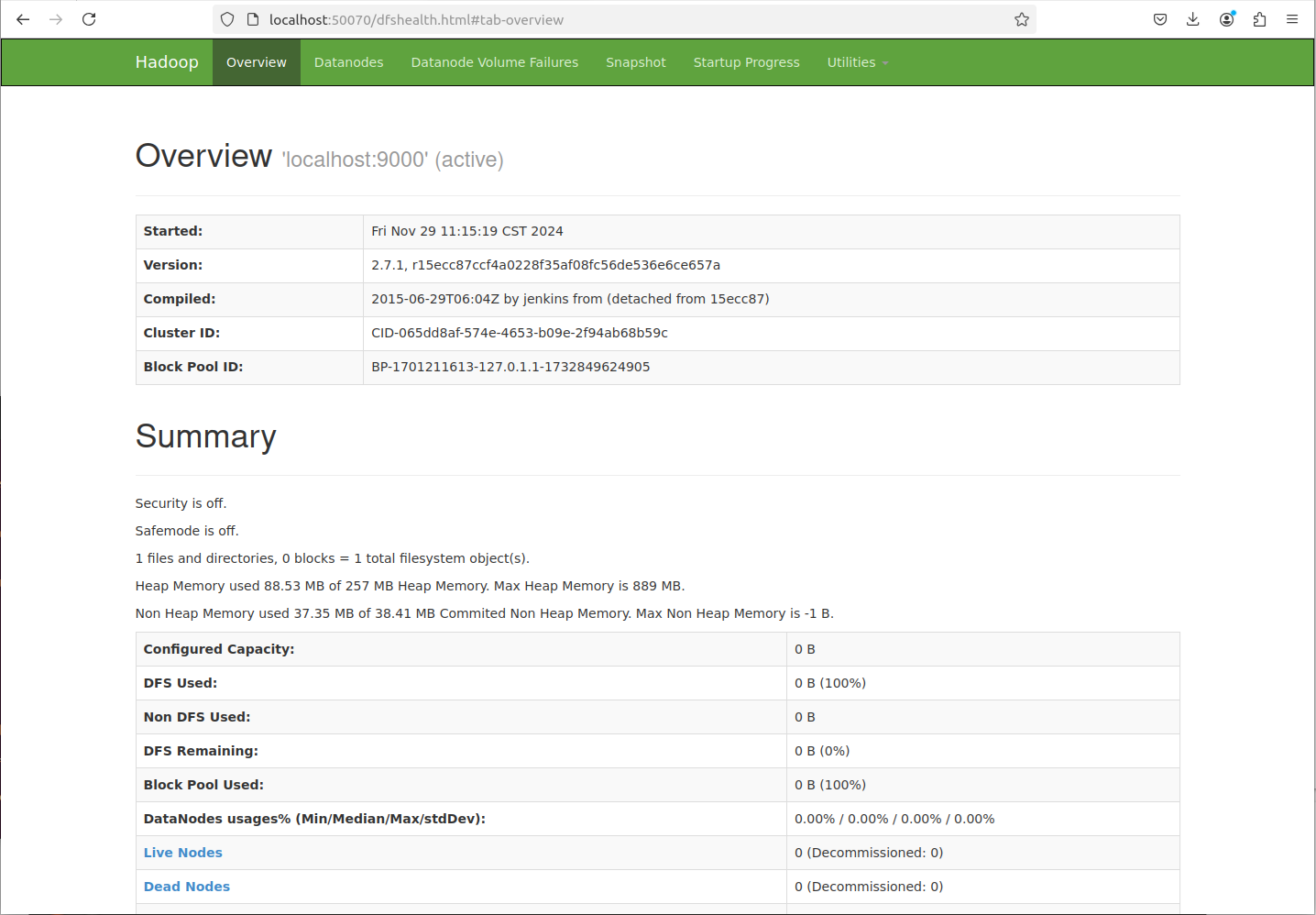
- 验证Hadoop运行状态:
使用jps命令查看Hadoop守护进程是否成功启动。 - 验证MapReduce作业:
检查MapReduce作业的输出结果是否符合预期。 - 访问HDFS:
使用Hadoop的文件系统命令在HDFS上进行文件操作,验证HDFS的功能。
具体结果图片见第二部分实验过程。
二、小结、建议及体会
在本次实验中,我们成功地安装并配置了Hadoop,从单机模式到伪分布式模式的转换让我们深入理解了Hadoop的架构,包括HDFS和MapReduce的工作原理,以及它们如何实现大规模数据的分布式存储和处理。实验过程中,我们学习了Linux环境下的关键操作,如用户管理、软件包更新、SSH无密码登录配置、Java环境安装和环境变量配置。此外,我们还探索了YARN资源管理器,它是Hadoop 2.x版本中负责资源管理和任务调度的重要组件。
建议在实际操作之前,通过书籍、在线课程或官方文档了解Hadoop的基本概念和架构,这将有助于更好地理解安装过程中的每个步骤。尝试安装不同版本的Hadoop,以了解它们之间的差异和兼容性问题,也是一个很好的学习方式。在掌握单机和伪分布式配置后,搭建一个小型的Hadoop集群可以进一步加深对分布式计算的理解。遇到问题时,学会查看日志文件、使用搜索引擎寻找解决方案,以及参与社区讨论,这些都是宝贵的技能。在生产环境中部署Hadoop时,还需要考虑安全性问题,如Kerberos认证和数据加密等。
通过次实验,我深刻体会到了大数据技术的深度。Hadoop的安装和配置涉及多个技术层面,从Linux系统管理到Java环境配置,再到Hadoop本身的架构理解。实验过程中遇到的问题,如环境变量配置错误、SSH连接问题等,提高了我的问题解决能力。我也意识到了持续学习的重要性,因为Hadoop和大数据领域不断发展,新技术和工具层出不穷。理论知识是基础,但亲自动手实践才能真正理解技术的精髓。在遇到难题时,我经常求助于在线社区和论坛,让我认识到了社区支持的力量。这次实践不仅加深了我对Hadoop的认识,也增强了我对未来技术挑战的信心。
参考文章:
参考链接
Hadoop的安装与伪分布式测试

