4.Iris与集成学习
摘要
第四次机器学习课程实验
仅供参考
- 将数据集按7:3 的比例随机划分为训练集和验证集,随机数生成器种子为学号后三位数431,并输出训练集和验证集前10行数据;
1 | from sklearn.datasets import load_iris |
<font size=1>训练集前10行数据:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 4.7 3.2 1.6 0.2
1 6.5 3.0 5.5 1.8
2 4.9 3.1 1.5 0.1
3 5.6 3.0 4.5 1.5
4 5.0 3.4 1.5 0.2
5 5.8 2.6 4.0 1.2
6 4.9 2.4 3.3 1.0
7 4.6 3.2 1.4 0.2
8 5.7 2.6 3.5 1.0
9 5.4 3.9 1.3 0.4
target
0 0
1 2
2 0
3 1
4 0
5 1
6 1
7 0
8 1
9 0
验证集前10行数据:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.4 3.7 1.5 0.2
1 6.7 3.3 5.7 2.5
2 5.0 2.0 3.5 1.0
3 5.1 3.5 1.4 0.3
4 4.4 3.0 1.3 0.2
5 4.7 3.2 1.3 0.2
6 6.4 2.9 4.3 1.3
7 4.4 3.2 1.3 0.2
8 5.7 3.0 4.2 1.2
9 5.1 3.3 1.7 0.5
target
0 0
1 2
2 1
3 0
4 0
5 0
6 1
7 0
8 1
9 0
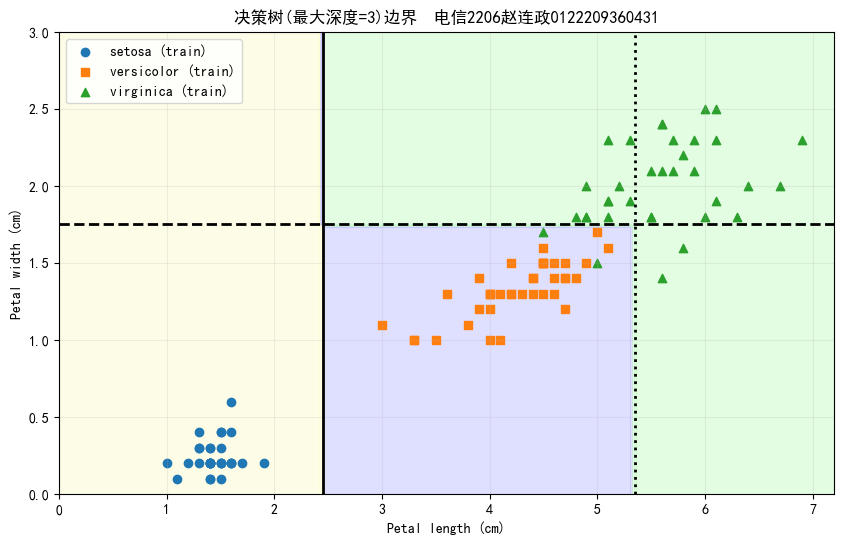
- 在训练集上训练决策树模型,生成如下的决策树边界
1 | from sklearn.tree import DecisionTreeClassifier |
- 在训练集上训练Bagging(基学习器自选)和随机森林模型,基学习器个数为100,输出决策边界图,并分析结果差异;
1 | from sklearn.ensemble import BaggingClassifier, RandomForestClassifier |
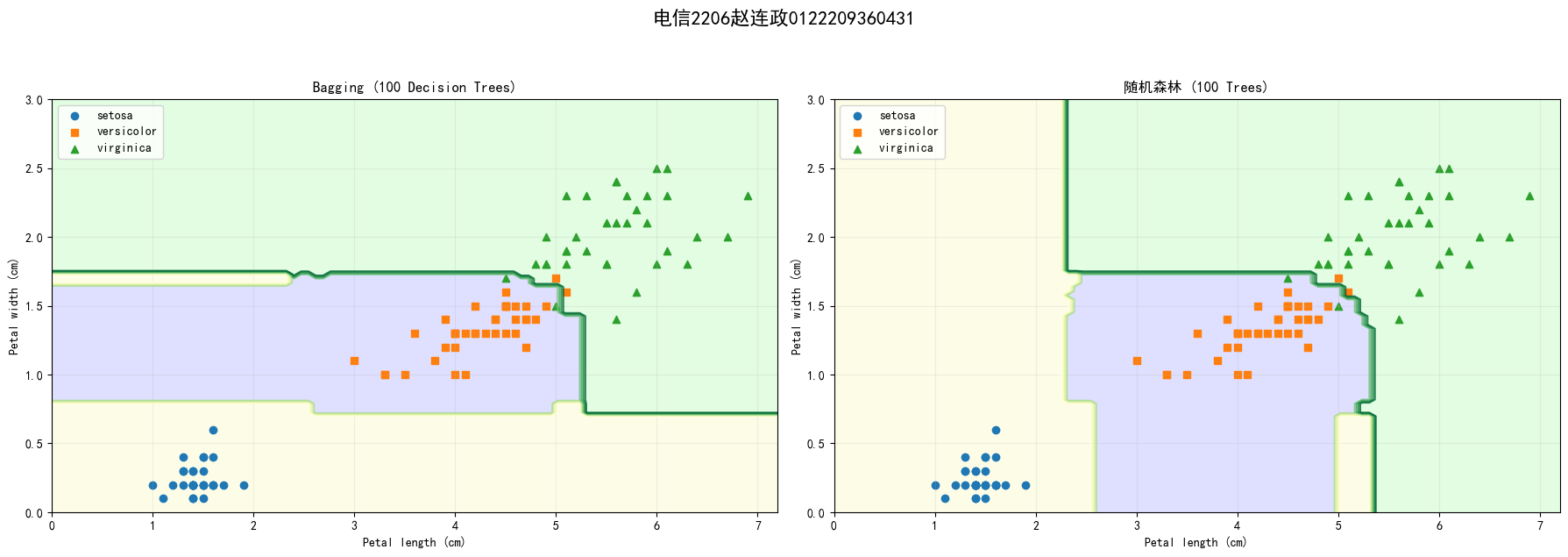
Bagging验证集准确率: 0.978
随机森林验证集准确率: 0.956
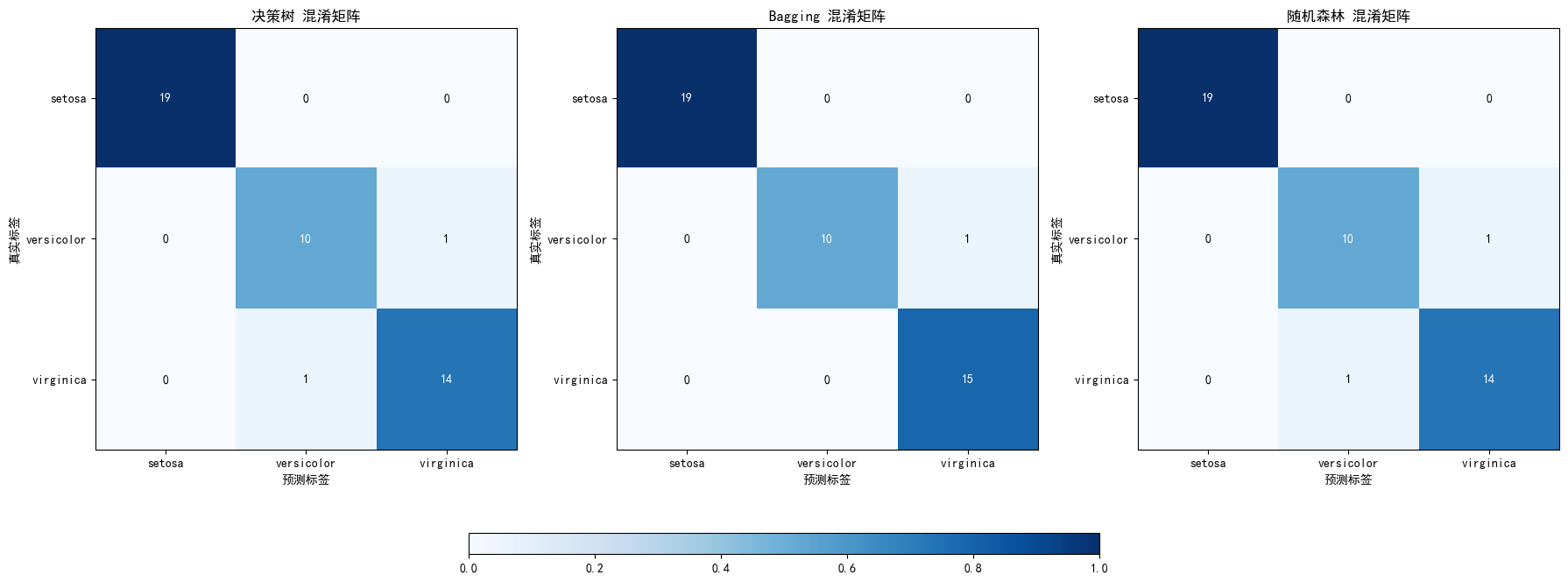
- 分别计算决策树、Bagging(基学习器自选)和随机森林模型在Iris数据集上三分类的混淆矩阵,并对三种算法的输出结果进行比较.
1 | # 计算混淆矩阵 |
决策树 混淆矩阵:
[[19 0 0]
[ 0 10 1]
[ 0 1 14]]
决策树 分类报告:
precision recall f1-score support
0 1.00 1.00 1.00 19
1 0.91 0.91 0.91 11
2 0.93 0.93 0.93 15
accuracy 0.96 45
macro avg 0.95 0.95 0.95 45
weighted avg 0.96 0.96 0.96 45
Bagging 混淆矩阵:
[[19 0 0]
[ 0 10 1]
[ 0 0 15]]
Bagging 分类报告:
precision recall f1-score support
0 1.00 1.00 1.00 19
1 1.00 0.91 0.95 11
2 0.94 1.00 0.97 15
accuracy 0.98 45
macro avg 0.98 0.97 0.97 45
weighted avg 0.98 0.98 0.98 45
随机森林 混淆矩阵:
[[19 0 0]
[ 0 10 1]
[ 0 1 14]]
随机森林 分类报告:
precision recall f1-score support
0 1.00 1.00 1.00 19
1 0.91 0.91 0.91 11
2 0.93 0.93 0.93 15
accuracy 0.96 45
macro avg 0.95 0.95 0.95 45
weighted avg 0.96 0.96 0.96 45
C:\Users\86182\AppData\Local\Temp\ipykernel_11464\1982013248.py:50: UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.
plt.tight_layout(rect=[0, 0.2, 1, 1]) # 调整布局以避免颜色条重叠